
The AI Code Revolution: Beyond Functionality to Long-Term Maintainability
Artificial intelligence is now generating code at an unprecedented rate, but long-term maintainability is a different challenge altogether. The rise of “vibe coding” – quickly generating functional code without prioritizing maintainability – in businesses has accelerated the problem. Common pitfalls include excessive reliance on third-party dependencies and complete rewrites of existing systems. This presents a significant hurdle for companies, heavily influenced by the underlying AI model they choose.
Introducing SWE-CI: A New Benchmark for Code Maintainability
To classify and evaluate the maintainability of code generated by Large Language Models (LLMs), researchers developed a new benchmark: SWE-CI. Unlike traditional code benchmarks that focus on fixing isolated bugs, SWE-CI assesses an AI’s ability to maintain software over time. The process involves providing the AI with an older version of a real-world, open-source software project (sourced from GitHub) and tasking it with evolving that version to the current release, feature by feature, through numerous modification cycles. On average, this represents 233 days of human development effort.
The AI isn’t given a list of changes to make; it must identify them independently. After each cycle, it analyzes the difference between its code and the target version, prioritizes issues, and implements corrections. This cycle repeats up to 20 times per task. The researchers evaluate the results using a proprietary metric called EvoScore, which prioritizes code quality at the end of the process. A model that produces clean, well-structured code from the start will have more flexibility later on, while one that relies on quick fixes will eventually struggle under its own weight.
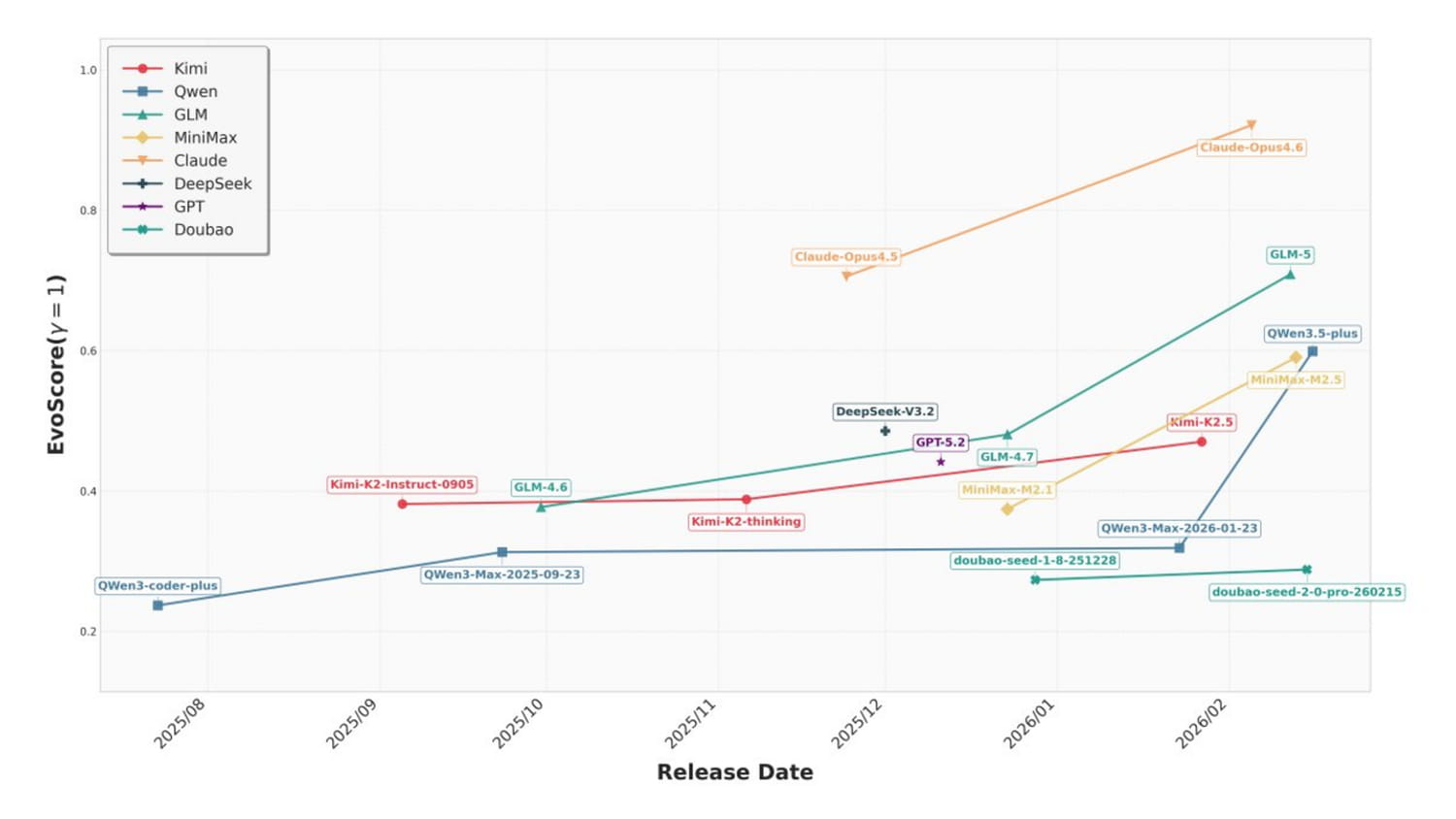
Claude Opus 4.6 Leads the Pack, But Challenges Remain
Eighteen models from eight different providers were evaluated. Claude Opus 4.6 significantly outperformed the others, achieving an estimated score of 0.85-0.90. Claude Opus 4.5 and GLM-5 followed with scores of 0.60-0.65. Qwen3.5-plus, MiniMax-M2.5, and Kimi-K2.5 scored around 0.45-0.50, while DeepSeek-V3.2 and GPT-5.2 fell into the middle range. Newer models consistently outperformed their predecessors, with a notable acceleration for those released after early 2026.
Perhaps more importantly, researchers measured each model’s ability to avoid breaking existing functionality while adding new code. Claude Opus 4.6 succeeded in 76% of tasks, while Claude Opus 4.5 achieved a 51% success rate. The performance dropped significantly for other models: Kimi-K2.5 and GLM-5 reached 37%, GPT-5.2 fell to 23%, and most models remained below 20%. Which means that, for the majority of LLMs currently available, the model breaks functional code in more than eight out of ten attempts to add new features.
The Future of AI-Assisted Development: A Focus on Maintainability
These findings highlight a considerable gap between the leading model and the rest of the field, particularly in the ability to avoid degrading existing code – a critical factor for long-term success. The researchers also noted that models released after 2026 are improving at a faster rate, indicating that providers are beginning to optimize for code maintainability, not just immediate functional correctness.
The benchmark remains incomplete, as several proprietary models (like Codex and Gemini) were not tested. However, SWE-CI provides a new dataset (available on Hugging Face) that companies can use to evaluate their own models over time. These initial results confirm what many developers have suspected: Claude Opus 4.6 excels at code maintenance tasks. Even the best models aren’t perfect, however, and can still introduce errors. Human oversight remains a crucial safety net.
FAQ: AI Code Generation and Maintainability
- What is SWE-CI? SWE-CI is a new benchmark for evaluating the maintainability of code generated by LLMs, focusing on long-term software evolution rather than isolated bug fixes.
- Which LLM currently performs best in code maintainability? According to the research, Claude Opus 4.6 currently leads in code maintainability, with a score of 0.85-0.90.
- Is human oversight still necessary when using AI for code generation? Yes, even the best LLMs can introduce errors. Human oversight, including code reviews and testing, remains crucial.
- What does “zero regression” mean in this context? Zero regression refers to the AI’s ability to add new code without breaking existing functionality.
Ready to explore more about AI in software development? Read our article on the integration of generative AI into the software development lifecycle.