The Shift Toward World Models: Why the Future of AI is Simulative, Not Just Generative
For years, the AI conversation has been dominated by Large Language Models (LLMs) that predict the next token in a sequence. But a fundamental shift is occurring. The industry is moving toward world models—learned systems that don’t just predict text, but act as differentiable simulators of reality.
A world model allows an AI to take a current state and a sequence of hypothetical actions to predict what will happen next. Essentially, it gives the AI a “mental sandbox” where it can roll forward through time, test strategies and optimize its path toward a goal before ever moving a physical actuator.
Solving the “Fragility” Problem in Long-Horizon Planning
Whereas the concept of a world model is powerful, putting it into practice is notoriously difficult. This is especially true for “long-horizon planning”—tasks that require a long sequence of actions to complete, such as navigating a complex room or repositioning an object before pushing it.

Traditional gradient-based planning often fails at scale due to three primary “traps”:
- The Gradient Vanishing Act: When differentiating through a model applied to itself repeatedly (Backpropagation Through Time), gradients can explode or vanish, making early actions nearly impossible to optimize.
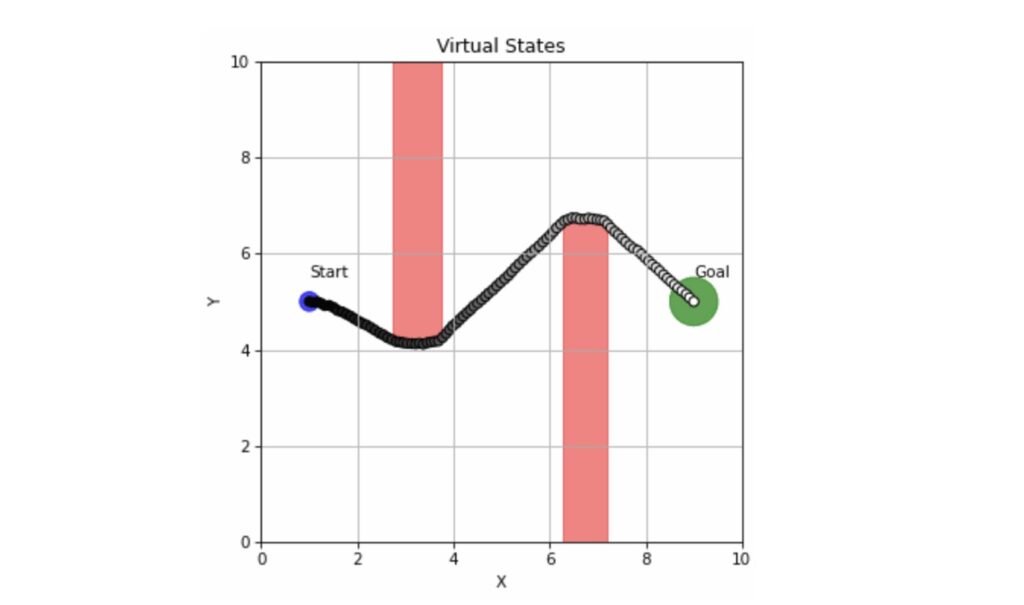
- Non-Greedy Landscapes: Many complex tasks require “non-greedy” behavior—like backing up to take a better path. Standard optimizers often get stuck in local minima, chasing the goal in a straight line and hitting a wall.
- Adversarial Brittleness: Deep learning models can be hypersensitive. Small, unseen changes in the state input can lead to wild predictions, a phenomenon similar to adversarial attacks in image recognition.
The GRASP Breakthrough: A New Blueprint for Robotics
To combat these issues, researchers including Yann LeCun, Michael Psenka, Mike Rabbat, Aditi Krishnapriyan, and Amir Bar have proposed GRASP (Gradient RelAxed Stochastic Planner). This approach fundamentally changes how AI “thinks” about its trajectory.
The Secret Sauce: Action Jacobians
The core insight of GRASP is that while state gradients (how the model reacts to changes in the environment) are brittle and adversarial, action gradients (how the model reacts to changes in the AI’s own moves) are stable and well-behaved.
GRASP leverages this by building a planner that depends primarily on action Jacobians. By “lifting” the trajectory into virtual states, the system can optimize across time in parallel, drastically speeding up the planning process.
Real-World Impact: Benchmarking Success
The effectiveness of this approach is most evident in high-stress tests like the “Push-T” task. As the planning horizon (H) increases, traditional methods like CEM (Cross-Entropy Method) and LatCo spot their success rates plummet.
Data indicates that at a horizon of H=80, GRASP maintains a success rate of 10.4%, significantly outperforming other gradient-based and sampling methods. More impressively, it does this while remaining faster; for example, at H=40, GRASP achieved success in a median time of 8.5 seconds, compared to 35.3 seconds for CEM.
Future Horizons: Where AI Planning is Heading
The success of GRASP opens the door to several emerging trends in autonomous systems:
Integration with Diffusion-Based World Models
There is significant potential in combining GRASP with diffusion models. Because diffusion can act as a “smoothed” version of a world model, it could further reduce the brittleness of planning in high-dimensional visual spaces.
Closed-Loop Adaptive Planning
The next step is moving from “open-loop” planning (calculating a whole path and executing it) to “closed-loop” systems. By integrating GRASP into RL (Reinforcement Learning) policy learning, robots could adapt their long-horizon plans in real-time as the environment changes.
Frequently Asked Questions
What exactly is a “world model” in AI?
A world model is a learned, differentiable simulator that predicts the future state of an environment based on a current state and a sequence of actions.
Why is long-horizon planning so difficult?
It suffers from exploding/vanishing gradients and “non-greedy” requirements, where the AI must move away from the goal temporarily to eventually reach it.
How does GRASP improve upon previous planners?
GRASP uses “lifted states” for parallel optimization and relies on stable action gradients rather than brittle state gradients, making it faster and more successful over long horizons.
Want to stay ahead of the AI curve?
The transition from generative AI to simulative world models is redefining robotics and autonomous agents. Join our newsletter for deep dives into the latest research from labs like BAIR and beyond.
Keep reading