
The Rise of AI-Powered Systematic Reviews: A New Era for Medical Research
Systematic literature reviews (SLRs) are the cornerstone of evidence-based medicine, but they’re notoriously time-consuming and resource-intensive. Now, a wave of innovation is transforming this process, leveraging the power of large language models (LLMs) like GPT-5 to accelerate discovery and improve the reliability of research synthesis. A recent study meticulously details how LLMs are being integrated into every stage of the SLR process, from initial search to evidence tiering.
Automating the Review Process: A Deep Dive
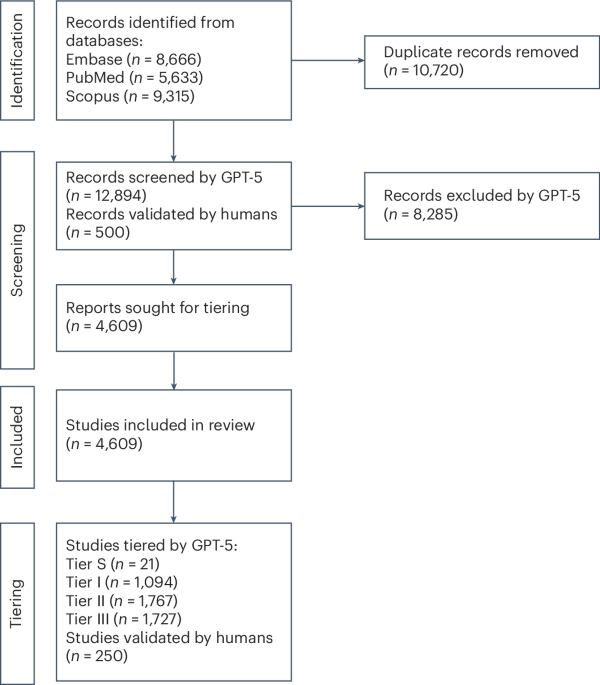
Traditionally, SLRs involve manual screening of thousands of studies, a process prone to human error and bias. Researchers are now employing LLMs to automate key steps. The study described a system for creating levels of evidence for LLM-based medical studies, then used a scalable, LLM-assisted framework to analyze published research evaluating LLMs in clinical medicine. This involved searching PubMed, Embase and Scopus, focusing on original research published between January 2022 and September 2025.
The search strategy wasn’t a simple keyword hunt. Researchers combined general LLM descriptors (“large language model,” “LLM”) with specific model names (GPT, ChatGPT, LLaMA, Claude, Gemini, and Bard). Crucially, they excluded review articles, meta-analyses, surveys, and commentaries to focus on original research. Specific database query strings were crafted for each platform – PubMed, Scopus, and Embase – to maximize precision.
GPT-5: The Screening and Tiering Powerhouse
With an overwhelming number of studies identified, manual screening was impractical. The researchers turned to GPT-5, utilizing its reasoning capabilities to classify studies as ‘include’ or ‘exclude’ based on whether they evaluated LLMs on clinical tasks. A blinded manual review of 500 randomly chosen studies validated the LLM’s performance.
But the automation didn’t stop at screening. GPT-5 was likewise used to ‘tier’ studies based on the robustness of their evidence. A four-tier system was implemented:
- Tier S: Real-world, prospective evaluations in live clinical environments.
- Tier I: Retrospective or prospective evaluations on real clinical data.
- Tier II: Simulated clinical situations and subjective patient ratings.
- Tier III: Board exams and multiple-choice tests.
This tiering system allows researchers to quickly assess the strength of the evidence supporting different LLM applications.
Validating AI with Human Expertise
Recognizing the need for validation, the researchers didn’t rely solely on the LLM. They compared GPT-5’s performance against human screeners and tierers, using statistical methods to quantify agreement and identify potential errors. This rigorous validation process is crucial for building trust in AI-assisted research.
Unsupervised Data Extraction: Unlocking Hidden Insights
Beyond screening and tiering, GPT-5 was employed for unsupervised data extraction, identifying key metadata from each study, such as the models evaluated, clinical specialties involved, and whether LLMs outperformed humans. This automated extraction streamlines the process of synthesizing information across numerous studies.
The Future of Systematic Reviews: Incremental Updates and Domain-Specific Models
The integration of LLMs isn’t just about speed; it’s about enabling a new paradigm for systematic reviews. The emergence of domain-specific finetuned LLMs, as highlighted in research from arXiv, promises even greater efficiency and scalability. PRISMA-DFLLM, an extension of the PRISMA guidelines, proposes a framework for leveraging these specialized models. This opens the door to “living systematic reviews” – continuously updated syntheses of evidence that reflect the latest research findings.
The ability to disseminate finetuned models empowers researchers to accelerate advancements and democratize cutting-edge research. As noted in a recent article in JMIR AI, transparent reporting of AI use in SLRs is paramount, leading to the development of PRISMA-trAIce, a checklist extension to ensure accountability and reproducibility.
Did you know? The number of studies evaluating LLMs in clinical medicine is rapidly increasing, making AI-assisted review methods essential.
Challenges and Considerations
While the potential benefits are significant, challenges remain. The study acknowledges the cost of benchmarking different LLM models and the need for ongoing validation. The lack of a prospectively registered protocol for this specific review highlights the importance of adhering to best practices for research transparency.
Pro Tip: When evaluating LLM-assisted research, always look for evidence of rigorous validation against human expertise.
FAQ
Q: What is PRISMA?
A: PRISMA (Preferred Reporting Items for Systematic Reviews and Meta-Analyses) is a set of evidence-based minimum items for reporting systematic reviews and meta-analyses.
Q: What are LLMs?
A: LLMs (Large Language Models) are artificial intelligence models that can understand and generate human-like text.
Q: How can LLMs help with systematic reviews?
A: LLMs can automate tasks like screening studies, extracting data, and assessing the quality of evidence.
Q: Is AI replacing human researchers?
A: No, AI is augmenting human researchers, allowing them to focus on more complex tasks and improve the overall quality of research.
Want to learn more about the latest advancements in AI and medical research? Explore our other articles or subscribe to our newsletter for regular updates.